Korma is a domain specific language for Clojure that takes the pain out of working with your favorite RDBMS. Built for speed and designed for flexibility, Korma provides a simple and intuitive interface to your data that won't leave a bad taste in your mouth.
DB2 NoSQL JSON enables developers to write applications using a popular JSON-oriented query language created by MongoDB to interact with data stored in IBM DB2 for Linux, UNIX, and Windows. This driver-based solution embraces the flexibility of the JSON data representation within the context of a RDBMS, which provides established enterprise features and quality of service.
We present the DataMeadow, a visual canvas providing rich interaction for constructing visual queries using graphical set representations called DataRoses. A...
http://www.cse.chalmers.se/~tsigas/papers/DataMeadow-InfoVis.pdf
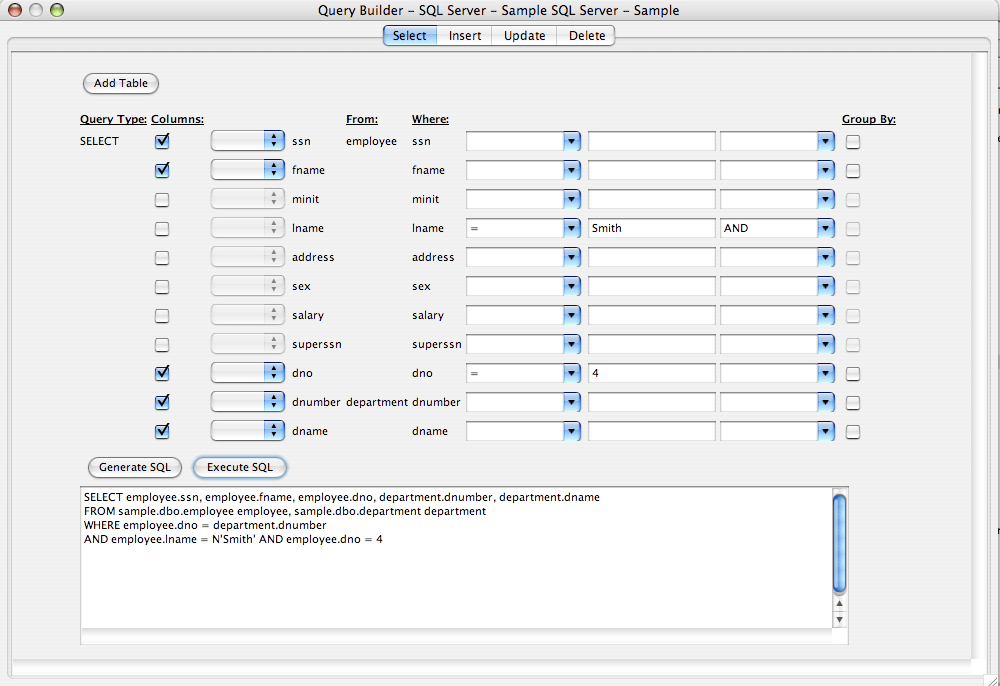
DbVisualizer offers features for database developers, analysts and DBAs. Read more about Database Object Management, SQL Script Management, Query Builder and more.
Learn how to use LINQ in your applications with these code samples, covering the entire range of LINQ functionality and demonstrating LINQ with SQL, DataSets, and XML.
MRQL (the Map-Reduce Query Language) is an SQL-like query language for map-reduce computations. It is implemented on top of Apache's Hadoop. MRQL is powerful enough to express most common data analysis tasks over many different kinds of raw data, including hierarchical data and nested collections, such as XML data. It is more powerful than other current languages, such as Hive and Pig Latin, since it can operate on more complex data and supports more powerful query constructs, thus eliminating the need for using explicit map-reduce code.
HTSQL was created in 2005 to provide an XPath-like HTTP interface to PostgreSQL for client-side XSLT screens and reports. HTSQL found its audience when analysts and researchers bypassed the user interface and started to use URLs directly. The language has evolved since then.
The Query Representation and Understanding (QRU) data set contains a set of similar queries that can be used in web research such as query transformation and relevance ranking. QRU contains similar queries that are related to existing benchmark data sets, such as TREC query sets. The QRU data set was created by extracting 100 TREC queries, training a query-generation model and a commercial search engine, generating similar queries from TREC queries with the model, and removal of mistakenly generated queries.
C. Batini, T. Catarci, M. Costabile, and S. Levialdi. Proceedings of the IFIP TC2/WG 2.6 Second Working Conference on Visual Database Systems II, page 153--168. Amsterdam, The Netherlands, The Netherlands, North-Holland Publishing Co., (1992)
B. Howe, G. Cole, N. Khoussainova, and L. Battle. Proceedings of the 2011 ACM SIGMOD International Conference on Management of data, page 1319--1322. New York, NY, USA, ACM, (2011)
K. Rohloff, and R. Schantz. Proceedings of the fourth international workshop on Data-intensive distributed computing, page 35--44. New York, NY, USA, ACM, (2011)
{kind=link}
{kind=link}